

Claude Opus 4.1: The AI Upgrade That’s More Hype Than Revolution
Hello everyone. Today, we’re diving into the latest announcement from Anthropic: the release of Claude Opus 4.1. Now, before you get too excited and start prepping your confetti cannons, let’s dissect this update with the precision of a neurosurgeon and the skepticism of a malpractice lawyer.
First off, Anthropic claims that Opus 4.1 is an “upgrade” to Opus 4, specifically targeting agentic tasks, real-world coding, and reasoning. They also tease us with the promise of “substantially larger improvements” in the coming weeks. Ah, the classic tech industry move—give you a taste now, dangle the carrot for later, and hope you don’t notice the stick poking you in the back.
Opus 4.1 is now available to paid Claude users, in Claude Code, and on their API, Amazon Bedrock, and Google Cloud’s Vertex AI. Pricing remains the same as Opus 4, which is a relief for those of us who don’t have a trust fund or a secret offshore account. But let’s be honest, “same pricing” in the AI world often means “still expensive enough to make your accountant break out in hives.”
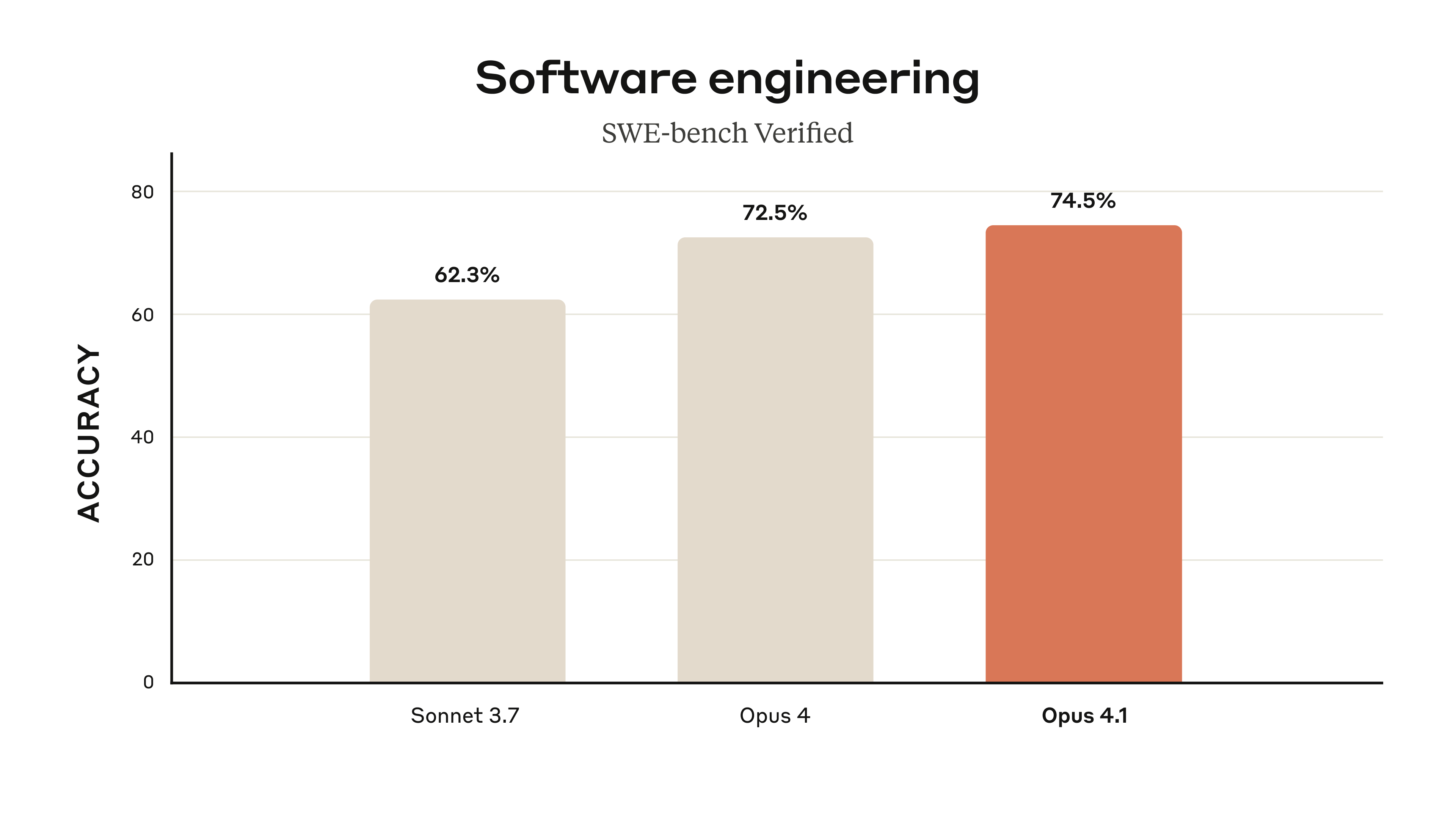
Now, let’s talk about the so-called “advancements.” Opus 4.1 boasts a state-of-the-art coding performance of 74.5% on some unspecified benchmark. They also claim improvements in in-depth research and data analysis skills, especially around detail tracking and agentic search. In other words, it’s supposed to be better at not losing its train of thought—a skill I wish some of my medical interns would develop.
The announcement is peppered with glowing testimonials from GitHub, Rakuten Group, and Windsurf. GitHub notes “notable performance gains in multi-file code refactoring.” Rakuten Group praises its “precision for everyday debugging tasks.” Windsurf reports a “one standard deviation improvement” over Opus 4 on their junior developer benchmark. One standard deviation, folks. That’s the kind of statistical mumbo-jumbo that makes you sound smart at conferences but means little to the average user. It’s like saying your new medication is “one standard deviation less likely to cause spontaneous combustion.” Comforting, but not exactly a ringing endorsement.
There’s also a benchmark table comparing Claude Opus 4.1 to prior Claude models and other public models. Spoiler alert: Opus 4.1 comes out on top. Shocking, I know. It’s almost as if companies only release benchmarks when they win. If only my medical board exams worked the same way—I’d be a triple board-certified genius by now.
For developers, upgrading is as simple as using “claude-opus-4-1-20250805” via the API. There’s also a smorgasbord of documentation, guides, and feedback forms to wade through. Because nothing says “user-friendly” like a labyrinth of PDFs and support tickets.
Now, let’s delve into the appendix, where the real fun begins. Data sources are meticulously listed, with links to OpenAI, Gemini, and previous Claude models. Benchmark reporting reveals that Claude models are “hybrid reasoning models,” whatever that means. Some benchmarks were achieved with “extended thinking”—up to 64K tokens. Extended thinking, folks. That’s corporate speak for “we let the AI ramble on until it stumbled upon the right answer.” It’s like giving a patient unlimited time to answer a memory test and then bragging about their perfect score.
The TAU-bench methodology involved a prompt addendum to both the Airline and Retail Agent Policy, instructing Claude to “better leverage its reasoning abilities while using extended thinking with tool use.” They even increased the maximum number of steps from 30 to 100, because apparently, more is always better. Most trajectories completed under 30 steps, with only one reaching above 50. So, in layman’s terms, it’s still a bit of a crapshoot.
SWE-bench methodology? They ditched the fancy scaffolding used in previous models and stuck with a bash tool and a file editing tool that operates via string replacements. No more hand-holding, just raw, unfiltered AI action. Scores for OpenAI models are reported out of a “full 500 problems,” but the details are as clear as a radiology report written in Sanskrit.

In summary, Claude Opus 4.1 is a marginal improvement over its predecessor, with some shiny new features and a lot of marketing fluff. It’s better at coding, supposedly more precise, and can handle more complex tasks—if you believe the carefully curated testimonials. But let’s not kid ourselves: this is an incremental update, not a revolutionary leap. It’s the AI equivalent of a new iPhone with a slightly better camera and a different shade of beige.
So, should you upgrade? If you’re already invested in the Claude ecosystem and have a penchant for bleeding-edge technology, go for it. Just don’t expect miracles. For the rest of us, it’s another reminder that the AI arms race is more about hype than substance.
And that, ladies and gentlemen, is entirely my opinion.
Source: Claude Opus 4.1, https://www.anthropic.com/news/claude-opus-4-1


{kind=link}