

GPT-5 Uncovered: The Ultimate Evolution in AI Refinement
Introduction
Hello everyone — after two weeks of daily use, GPT-5 has left me with the distinct impression that OpenAI’s latest flagship is less a wild new frontier and more a well-tuned sports car. It’s not breaking physics, but it is sticking every corner with precision. Across writing, coding, reasoning, and a sprinkling of image handling for prompts, GPT-5 feels like an all-rounder that rarely drops the ball — and when it does, it at least fumbles gracefully.
Key Characteristics
GPT-5’s architecture is a hybrid in ChatGPT: it juggles a “fast” default model, a deeper “thinking” model, and a routing layer that switches based on complexity, tools needed, and user intent (even reacting to prompts like “think hard about this”). Once you hit usage limits, smaller “mini” versions take over. API users get a simpler setup: GPT-5, GPT-5 Mini, and GPT-5 Nano — each tunable to four reasoning modes (Minimal, Low, Medium, High).
- Input limit: 272,000 tokens
- Output limit (including invisible “reasoning” tokens): 128,000
- Multimodal input (text + images), text-only output
- Knowledge cut-off: Sept 30, 2024 (main), May 30, 2024 (Mini & Nano)
The result? A model that exudes competence — rarely requiring a reprompt or a fallback to another LLM. But it’s not a paradigm shift; think refinement over reinvention.
Position in the OpenAI Model Family
GPT-5 aims to consolidate much of OpenAI’s previous lineup. “gpt-5-main” replaces GPT-4o, “gpt-5-thinking” takes over from o3 and o4-mini, and Nano models slot where the lighter GPT-4.1 versions lived. The premium “GPT-5 Pro” — an extended compute “thinking-pro” variant — is paywalled at $200/month.
Notably absent: audio I/O and image generation, still handled by Whisper, GPT-4 Vision, and DALL·E models.
Pricing and Value
- GPT-5: $1.25/million input tokens, $10/million output tokens
- GPT-5 Mini: $0.25/m input, $2/m output
- GPT-5 Nano: $0.05/m input, $0.40/m output
Compared to GPT-4o, GPT-5 halves the input cost while keeping output costs steady. Given that “reasoning” tokens are billed as output, you may see higher output costs unless you drop the reasoning_effort to Minimal.
Token caching gets a massive 90% input discount for recently reused tokens — a game changer for chat UI and multi-turn conversation setups.
Performance and Reliability
According to system card notes, OpenAI focused on reducing hallucinations, improving instruction following, and cutting sycophancy. Early impressions match the claims: in two weeks, no obvious misfires, and accuracy is on par with or better than Claude 4 and o3 in everyday use. Updated browsing behaviors mean fresh info is handled more effectively, though many API calls still operate without browsing.
Safety and Ethics
The “safe-completions” approach replaces blunt refusals with moderated responses designed to avoid harmful details while still providing something useful. Dual-use topics like biology or cybersecurity get a “helpful but regulated” output rather than a hard stop. Sycophancy was explicitly targeted in post-training with evaluation-driven reward signals.
The model admits failure in impossible cases rather than fabricating — particularly where tools are intentionally disabled. This is a notable trust upgrade over past LLM behavior.
Prompt Injection
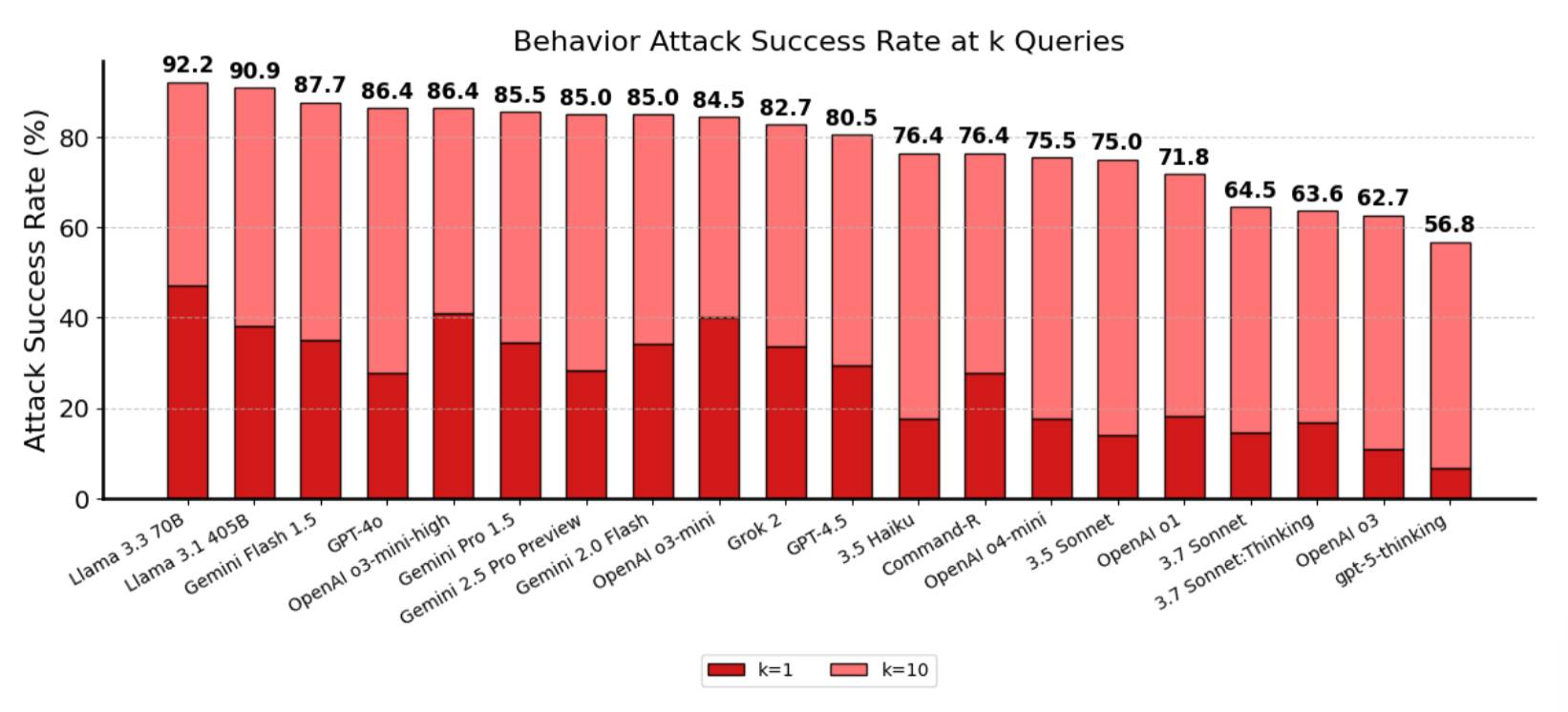
Internal red-teaming shows gpt-5-thinking with a 56.8% attack success rate in k=10 attempts — better than peers but still a concerning baseline. Translation: prompt injection remains unsolved; be wary in production apps.
Developer Options
The API allows reasoning summaries with "reasoning": {"summary": "auto"} and lets you dial reasoning effort down for faster token streaming. This control is especially relevant for latency-sensitive or real-time applications.
The Fun Experiment: Pelican on a Bicycle
Because no model review is complete without whimsical testing, the author asked GPT-5 variants to draw SVG pelicans riding bicycles. GPT-5 nailed it with correct bike frames and a recognizably pelican beak; Mini added some odd features like dual necks; Nano produced something… minimal. Verdict: even its “artistic” reasoning scales smoothly with model size.

The Big Caveats
While speed, competence, and pricing are all wins, the limitations are clear:
- No audio or image generation
- Prompt injection mitigation still incomplete
- High output billing from reasoning tokens unless carefully managed
- Knowledge cut-off dates not bleeding-edge fresh
GPT-5 is less a revolution and more a surgical refinement — sharper edges, better control, same basic blade.
Verdict
Cautious Recommend. GPT-5 delivers high competence at competitive prices, making it a strong default for multipurpose LLM work. But developers and businesses should budget for reasoning token usage, implement serious prompt-injection checkpoints, and remember that it’s an evolution, not a leap.
And that, ladies and gentlemen, is entirely my opinion.
Article source: GPT-5: Key characteristics, pricing and system card, https://simonwillison.net/2025/Aug/7/gpt-5/
{kind=link}