

Google’s Insane 10,000X Data Reduction: Revolutionary Breakthrough or Overhyped Marketing Stunt?
Hello everyone. Today we’re diving headfirst into Google’s latest brainchild – a supposedly miraculous “active learning curation process” that promises to train LLMs for complex ad moderation tasks using up to 10,000 times less data than before. Big promise, shiny graphs, and enough buzzwords to choke a marketing department. But does it really live up to its god-tier hype, or is it another example of overclocking the benchmarks for a flashy keynote before stability testing? Let’s talk.
The Elevator Pitch: Magical Data Diets for LLMs
The claim: Instead of stuffing your model with 100,000 samples like a kid overdosing on digital Skittles, you can feed it under 500 expertly-curated examples and still get top-tier performance. Specifically, they tout a 65% improvement in “model-human alignment” versus your bog-standard, mass-produced, crowdsourced-label soup. Sounds delicious – if you ignore the part where the secret ingredient is “expensive, highly skilled human experts” instead of “mechanical turk workers making $0.02 a label”.
The gist: Train a zero- or few-shot model, use it to label a massive dataset, find where it’s most confused, have experts settle the debate, rinse and repeat until your accuracy peaks or you get bored. It’s basically giving the model therapy sessions on the very moments where its sanity breaks down. And yes, it’s genuinely clever… but also the ML equivalent of “Hey, just curate the content better,” which is about as groundbreaking as telling a hospital to improve survival rates by “just treating the sickest patients first.”

The Devil’s in the Metrics
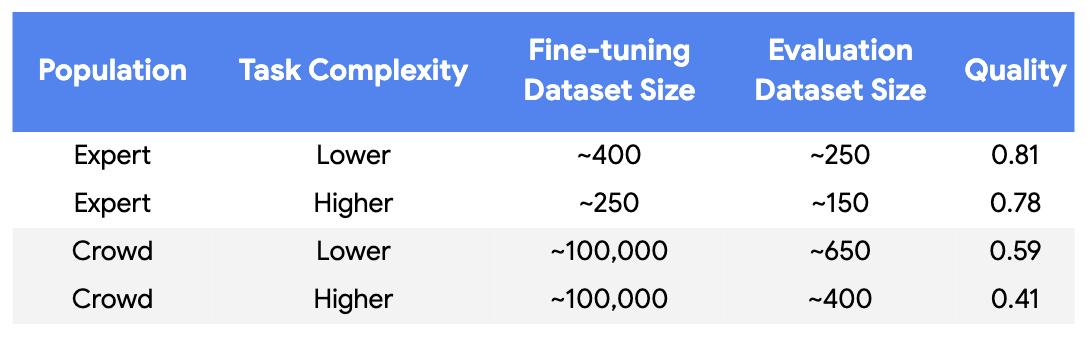
Let me be blunt here: they don’t even pretend there’s a real “ground truth” in content moderation. Ads safety is inherently subjective. So instead of precision or recall, they use Cohen’s Kappa – a statistical measure of agreement between two annotators, adjusted for chance. 0.8 and above? Gold star. Below 0.4? You’re basically arguing with yourself in a mirror.
The curated approach hits 0.81 and 0.78 for two advertised “complexity levels,” which is honestly excellent. Crowdsourced data? Try 0.59 and 0.41. That’s about the difference between a surgeon with steady hands and an intern trying to stitch a wound while watching TikTok.
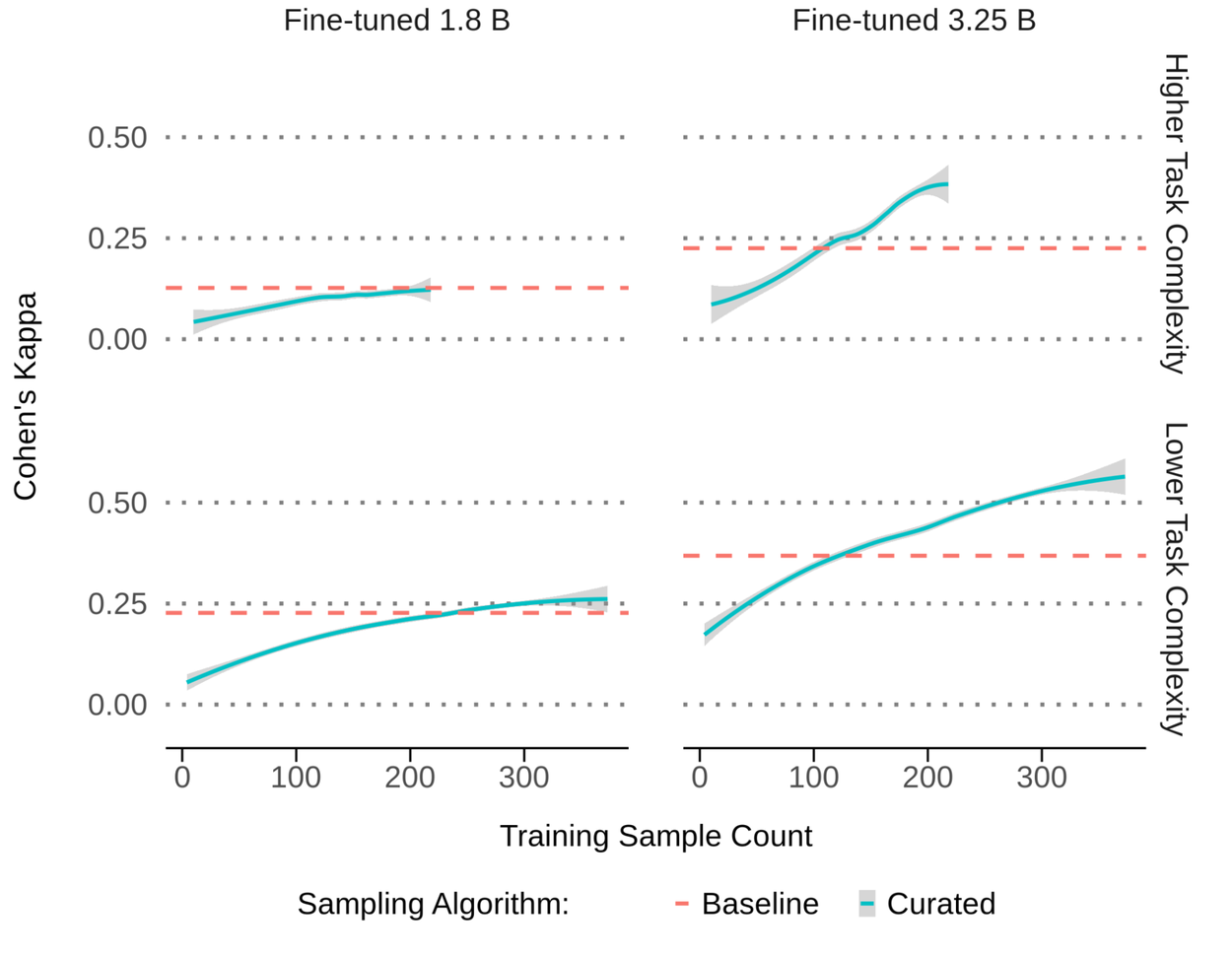
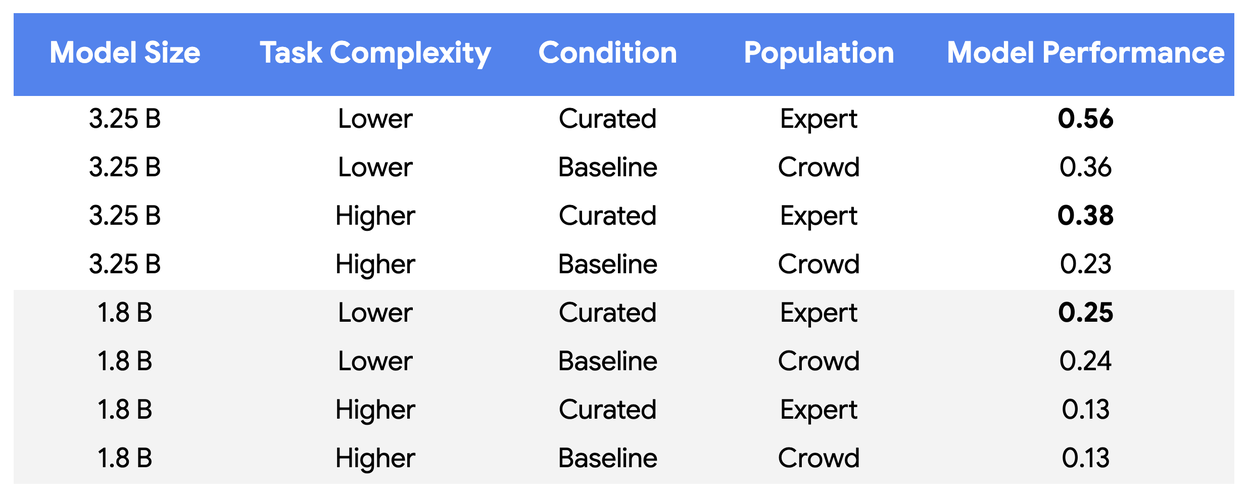
The Small Model Problem
Now here’s where reality sucker-punches the hype. On the smaller 1.8B parameter model, data curation barely moved the needle. We’re talking .24 to .25 alignment on the easy task, and no change at all on the hard task. It’s like swapping the tires on a shopping cart – sure, the ride feels smoother, but you’re still not winning Formula 1 with it.
Only when they cranked things up to the 3.25B model did the magic show up. And yes, performance leapt 55–65% while using three orders of magnitude less data. But this paints the picture of a method that only flexes its muscles if your model’s already buff enough to handle the weights. Initiative players with low-level gear will still get bodied by the boss fight.
The Conspiracy Angle
Let me put on my tinfoil headset for a moment: This smells like a move to cut costs under the guise of shiny research. Sure, they’ll spin it as “saving the planet with fewer GPU hours” and “making AI more accessible,” but really? This is about not having to pay armies of labelers while still claiming superior results. It’s the Silicon Valley way – repackage frugality as genius efficiency and watch the stock ticker twitch upwards.
It also nicely entrenches the power dynamic: only orgs with access to top-tier models AND top-tier human expertise can replicate this “miracle.” Crowdsourcers? Stay in your lane.
The Doctor’s Note
As a humble medical analogy: This is triage done properly – identify the patients in most immediate need of intervention and focus all your best surgeons on them. Done right, you save more lives with fewer resources. But make no mistake – you still need expensive surgeons, a functioning OR, and a patient list worth caring about. Without those, this is just another PowerPoint cure-all; and the only thing you’ll be resuscitating is your budget spreadsheet.

Final Boss Fight Verdict
Let’s be clear: This is impressive research. The numbers aren’t snake oil; the technique clearly works under the right conditions. It’s elegant in its focus, pragmatic in execution, and could genuinely help in domains where expertise is scarce and expensive. But it’s not a free buff for everyone – it’s more of a late-game legendary weapon that’s useless if you haven’t ground for the prerequisites.
So yes, hats off – but let’s not pretend that this will suddenly democratize AI training. This is elite gear for elite teams, and the average player is still farming goblins with their basic starter kit.
Verdict: Technically brilliant, strategically useful, but realistically limited in its accessibility. Powerful endgame tech, not a casual-friendly patch note.
And that, ladies and gentlemen, is entirely my opinion.
Article source: Achieving 10,000x training data reduction with high-fidelity labels


{kind=link}