

Chain-of-Thought AI Is Dead: Stop Pretending These Bots Actually Reason
Hello everyone. Today, let’s put on the gloves and perform some exploratory surgery on the so-called miracle cure of AI’s latest party trick – Chain-of-Thought reasoning. This is that fancy process where the model supposedly “works through” logical steps like a patient solving a Sudoku while sipping herbal tea. Spoiler: it’s more like a drunk intern reading the answer key upside down.
The Hyped Diagnosis
The AI industry has been swinging this shiny chain-of-thought like a Twitch streamer swinging their gamer chair when they lose. The promise? Models that can parse complex, multi-step problems with Sherlock Holmes-like finesse. The reality? Models that crack under pressure faster than a bargain-bin controller during a Dark Souls boss fight.
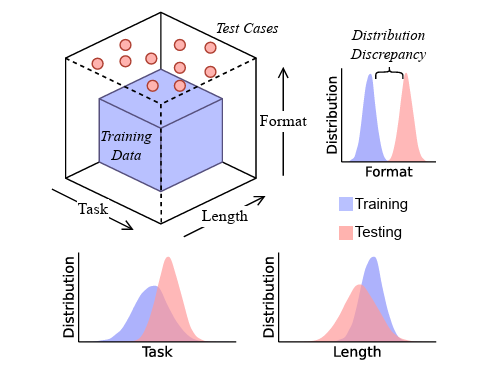
Some researchers from the University of Arizona – bless them – decided not to take the press release at face value. They built a controlled LLM “lab” to stress test how well these supposed reasoning machines handle anything that deviates from their training patterns. The verdict? “Largely a brittle mirage,” which in doctor-speak is the equivalent of saying: “This patient looked fine until we asked them to walk up a single flight of stairs… then they coded on the spot.”
The Case Study: Out-of-Domain Disaster
They trained small models on two very basic text functions – think of it as teaching a med student how to take a pulse and write it down. Then, without warning, they asked the models to do variations they’d never seen before. This is where the fun began… or horror, depending on your perspective.
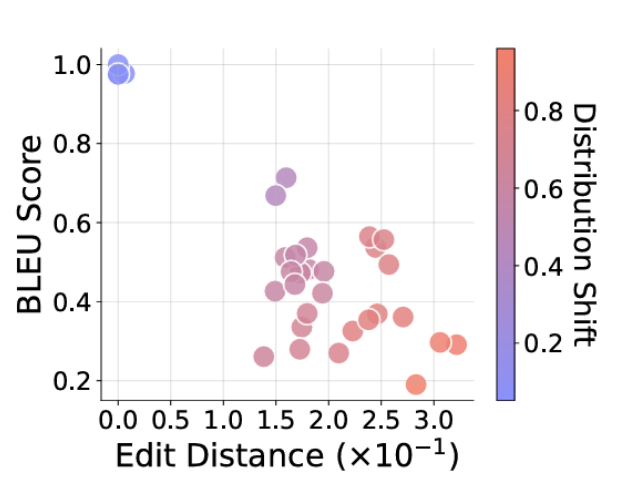
- Sometimes the model produced the correct reasoning steps with the wrong answer.
- Other times it got the right answer with hilariously illogical reasoning paths.
- When format or length differed even slightly from the familiar, accuracy dropped faster than a dodgy Wi-Fi connection mid-raid.
In gaming terms, it’s like knowing every dodge pattern for a boss fight but still rolling straight into their sword because the lighting changed slightly in the new dungeon.
The False Aura of Competence
The study makes the brutally honest point: these models aren’t doing algebra in their silicon brains, they’re just exceptionally good at matching patterns they’ve seen before. Push them even a few inches out of their cozy data comfort zone and they crumble into “fluent nonsense” – which is exactly what it sounds like. You get confident, articulate garbage. Like a conspiracy theorist in a suit, eloquent but utterly detached from reality.
“A false aura of dependability.”
Sure, you can use supervised fine-tuning as a duct-tape repair job to patch the holes, but that’s not a cure – it’s just changing the bandages without treating the infection. The researchers call it unsustainable, and in gaming logic, that’s like hot-fixing a bug that crashes the game but leaving the core exploit in place – you know it’ll break again the next time someone pokes it too hard.
Why It Matters (Especially Outside the Arcade)
This isn’t just academic nitpicking. In medicine, finance, or legal work, mistaking this pattern-matching mimicry for actual human-grade reasoning is asking for absolute catastrophe. Imagine your surgeon’s reasoning chain is basically “previous patients had a left lung… so I removed the right one this time for variety.”
The takeaway? We need testing that deliberately works outside an AI’s training playground to see if it can adapt or if it’s just overfitted to pass yesterday’s exam. Until then, touting coT reasoning as “human-like” is selling snake oil in a shiny blockchain-powered bottle.
Final Prognosis
Chain-of-thought reasoning in its current form? Flashy in the demo, brittle in the wild. More cosplay than combat, more scripted cutscene than genuine AI gameplay. Until models learn to actually reason abstractly instead of just replaying memorized patterns, don’t mistake eloquence for intelligence. In my completely biased, totally correct opinion – the hype is the real hallucination here.
And that, ladies and gentlemen, is entirely my opinion.





Article source: LLMs’ “simulated reasoning” abilities are a brittle mirage, https://arstechnica.com/ai/2025/08/researchers-find-llms-are-bad-at-logical-inference-good-at-fluent-nonsense/


{kind=link}